Nouvelles
Jetez un coup d'œil aux dernières nouveautés en matière de vision par ordinateur lors de la CVPR 2022 : troisième partie

Tina Behrouzi, résidente en apprentissage automatique, nous fait part de ses impressions sur ce qu'elle a vu à la conférence CVPR 2022 de cette année.
Tina Behrouzi est résidente en apprentissage automatique au sein de l'équipe Advanced Tech d'Amii. Une grande partie de son travail porte sur la vision par ordinateur, en particulier sur les modèles génératifs profonds pour les tâches de vision. Dans cet article, elle partage quelques-unes des avancées qui l'ont le plus enthousiasmée lors de la conférence de cette année sur la vision informatique et la reconnaissance des formes à la Nouvelle-Orléans.
Dans les parties un et deux de cette série, j'ai examiné les progrès récents des transformateurs de vision multi-échelles (MViT) et de leurs variantes. Maintenant, je veux me concentrer sur deux techniques qui ont un impact important sur la façon dont les modèles de vision par ordinateur sont formés : la distillation des connaissances et l'apprentissage continu.
Distillation des connaissances : Un bon professeur est patient et constant
De nombreux réseaux de vision par ordinateur sont assez profonds et ont une vitesse d'inférence lente, ce qui rend leur déploiement en production difficile et coûteux. La distillation des connaissances (KD) est une technique permettant de former un modèle étudiant plus petit, plus rapide et plus rentable sous la supervision d'un modèle enseignant complexe et puissant.
La distillation des connaissances (KD) est populaire pour la compression des modèles. Au lieu d'utiliser un seul mode complexe et gourmand en ressources, la KD utilise un modèle professeur qui est pré-entraîné sur des données, puis transmet ses résultats à un modèle étudiant moins complexe sur lequel il s'entraîne. Le réseau étudiant peut potentiellement avoir besoin de moins d'espace de stockage, prendre moins de temps ou fonctionner sur un matériel moins puissant que le réseau enseignant.
De plus, le réseau de l'enseignant tient compte des effets de l'augmentation des données, qui peut résoudre le problème de l'insuffisance des données d'entraînement en générant de nouveaux points de données artificiels à partir de ceux qui existent déjà. En faisant passer les données générées par l'enseignant pour estimer la probabilité de sortie, des éléments comme l'annotation humaine ne sont pas nécessaires pour étiqueter les données augmentées.
Enfin, dans de nombreux réseaux profonds de vision par ordinateur, qui sont formés de bout en bout, différents sous-modules du réseau sont conçus pour traiter des tâches spécifiques. Dans un modèle de vision par ordinateur conçu pour échanger deux visages, par exemple, un module pourrait être chargé de déterminer les principales caractéristiques du visage, tandis qu'un autre pourrait s'occuper de déterminer la position du visage dans l'image. KD permet de fournir des étiquettes pour la formation de ces réseaux de sous-modules.
Correspondance de fonctions (FunMatch) :
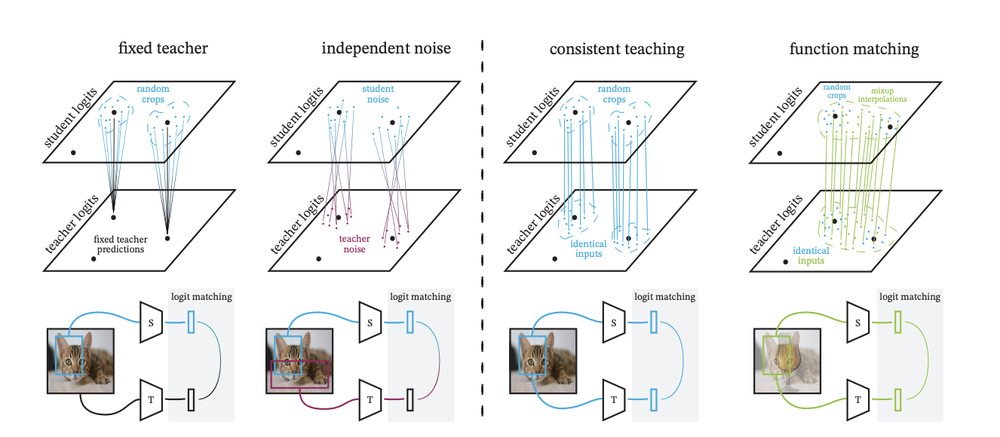
Comparaison du FunMatch avec d'autres techniques de distillation (Beyer, 2022)
Dans FunMatch, l'équipe de Google Research présente la meilleure procédure et le meilleur cadre actuels pour former un réseau d'étudiants. Ce travail s'attaque au défi du transfert de modèles à grande échelle en petits modèles à un coût efficace. FunMatch présente trois étapes importantes qui doivent toutes être appliquées ensemble dans le transfert de connaissances pour obtenir les meilleurs résultats. Par exemple, il souligne qu'une entrée exacte avec la même augmentation et le même recadrage doit être transmise aux modèles de l'enseignant et de l'élève.
FunMatch a montré la meilleure performance de Resnet50, un réseau neuronal convolutif populaire, entraîné sur la base de données d'images ImageNet avec une augmentation de plus de 2% de la précision par rapport aux modèles de pointe. Cependant, l'un des défis est que cette méthode ne peut pas être appliquée à la prédiction de l'enseignant précalculée d'une image faite hors ligne.
CaSSLe : Les modèles auto-supervisés sont des apprenants continus
L'apprentissage continu (AC), parfois appelé apprentissage permanent, a suscité beaucoup d'intérêt dans de nombreux domaines de l'apprentissage automatique. L'idée est d'entraîner en permanence un réseau sur la base de nouvelles données sans perdre les informations précédentes. Les modèles basés sur l'apprentissage continu y parviennent généralement en conservant une partie du réseau intacte tout en optimisant les autres sections. Un bon apprenant continu saisit les propriétés des données qui changent constamment dans le temps. La CVPR de cette année a été marquée par de nombreux travaux sur l'apprentissage continu pour les tâches de vision, afin d'améliorer l'applicabilité à long terme des modèles de vision par ordinateur.
L'un des principaux défis de l'apprentissage continu en vision est que les réseaux de vision par ordinateur sont généralement coûteux et profonds, ce qui rend l'expansion des paramètres de toutes les couches peu pratique. Pour que le coût de calcul reste raisonnable, les chercheurs n'appliquent le paradigme de l'apprentissage continu qu'à des couches spécifiques et à une partie seulement d'un réseau. Par conséquent, ils doivent trouver la couche la plus efficace à développer.
Presque tous les modèles actuels performants qui utilisent le CL en vision sont formés selon une approche supervisée. C'est pourquoi le modèle CaSSLe, qui fonctionne avec des modèles auto-supervisés, a retenu mon attention lors de la conférence.
CaSSLe :
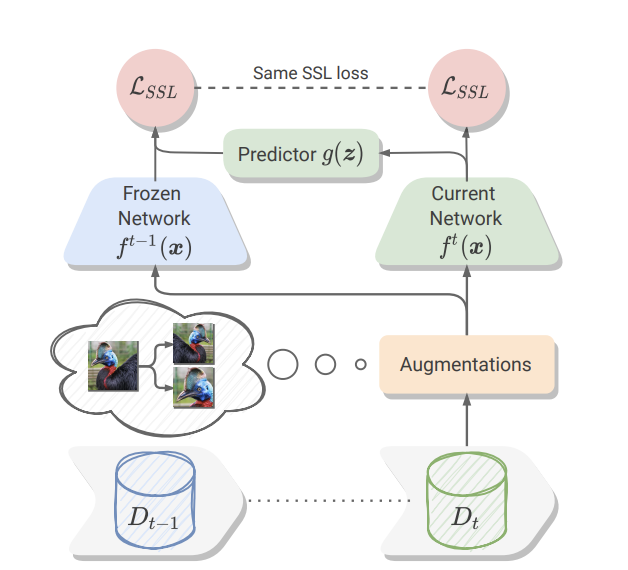
Aperçu du cadre CaSSLe (Fini, 2022)
CassLe est un cadre pour l'entraînement continu d'un modèle auto-supervisé. Ce travail mentionne que les techniques de régularisation de CL sont préjudiciables dans un cadre auto-supervisé. De plus, pour être efficace, la méthode CL doit être compatible avec les modèles auto-supervisés actuels. Par conséquent, CaSSLe introduit deux approches pour faire face à ces problèmes :
Premièrement, CaSSLe utilise une technique de distillation pour apprendre de nouvelles informations basées sur des prédictions précédentes. Ensuite, un modèle prédicteur est conçu et appliqué aux nouvelles caractéristiques pour les transférer dans un nouvel espace. De cette façon, les nouvelles et anciennes caractéristiques ne sont pas comparées une par une, ce qui aide le réseau à apprendre de nouvelles connaissances.
CaSSLe réduit la taille des données nécessaires au pré-entraînement d'un réseau. En outre, CaSSLe est simple et compatible avec les modèles autosupervisés les plus récents. De plus, l'auteur affirme qu'un réglage supplémentaire des hyperparamètres n'est pas nécessaire par rapport à la méthode auto-supervisée originale.
Cependant, la sauvegarde des poids des codeurs précédents et l'ajout de réseaux prédicteurs supplémentaires rendent la méthode CaSSLe coûteuse en termes de calcul - elle peut augmenter de 30 % le coût en mémoire et en temps d'un réseau auto-supervisé.
La distillation des connaissances a déjà remporté un énorme succès en vision par ordinateur. Lors de la CVPR de cette année, FunMatch a introduit un cadre meilleur et plus général pour KD. De plus, CassLe a présenté un nouveau mécanisme pour l'apprentissage continu d'une structure de modèle auto-supervisé dans ce monde en constante évolution. Je pense que ces deux techniques d'apprentissage seront essentielles à la construction de réseaux légers et adaptatifs dans l'avenir de la CV.
L'équipe Advanced Tech d'Amii aide les entreprises à utiliser l'intelligence artificielle pour résoudre certains de leurs défis les plus difficiles. Découvrez comment elle peut vous aider à à exploiter le potentiel des dernières avancées en matière d'apprentissage automatique.
Derniers articles d'actualité

8 avril 2024
Nouvelles
Déchiffrer le code de la conférence
Les boursiers d'Amii partagent des conseils sur la manière de tirer le meilleur parti de votre expérience de la conférence.

26 mars 2024
Nouvelles
Comment le Chat GPT a ruiné le Noël d'Alona | Approximately Correct Podcast
Dans l'épisode de ce mois-ci, Alona explique comment ChatGPT a changé la perception qu'a le public de ce que les modèles de langage d'IA peuvent faire, rendant instantanément obsolètes la plupart des références antérieures, et parle de l'excitation et de l'intensité du travail dans un domaine qui évolue rapidement comme l'IA.

18 mars 2024
Nouvelles
Google Canada annonce de nouvelles subventions de recherche pour renforcer l'écosystème de l'IA au Canada
Google.org annonce de nouvelles subventions de recherche pour soutenir la recherche critique sur l'IA au Canada, axée sur des domaines tels que la durabilité et le développement responsable de l'IA. Les subventions accordées à Amii, à l'Institut canadien de recherches avancées (CIFAR) et au Centre international d'expertise de Montréal sur l'IA (CEIMIA) s'élèvent à un total de 2,7 millions de dollars.
