Nouvelles
Jetez un coup d'œil aux dernières nouveautés en matière de vision par ordinateur lors de la CVPR 2022 : deuxième partie

Tina Behrouzi, résidente en apprentissage automatique, nous fait part de ses impressions sur ce qu'elle a vu à la conférence CVPR 2022 de cette année.
Tina Behrouzi est résidente en apprentissage automatique au sein de l'équipe des technologies avancées d'Amii. Une grande partie de son travail porte sur la vision par ordinateur, en particulier sur les modèles génératifs profonds pour les tâches de vision. Dans cet article, elle nous fait part de quelques-unes des avancées qui l'ont le plus enthousiasmée lors de la Conférence sur la vision par ordinateur et la reconnaissance des formes de cette année à la Nouvelle-Orléans.
Dans la première partie de la série, elle examine le transformateur de vision multi-échelle (MViT) et son amélioration par rapport aux précédents transformateurs de vision (ViT). Ici, elle décrira deux nouveaux modèles MViT présentés lors de la conférence de cette année. Et la troisième partie portera sur les avancées en matière d'apprentissage continu et de distillation des connaissances.
Dans mon dernier article, j'ai évoqué les progrès passionnants réalisés au cours des deux dernières années par les transformateurs de vision et la manière dont ils utilisent certaines des leçons apprises dans le cadre du traitement du langage naturel pour créer de meilleurs outils d'analyse des images et des vidéos. Voyons maintenant quelques variantes de la formule MViT (Multiscale Vision Transformers) et comment elles sont conçues pour résoudre des problèmes spécifiques dans le monde de la vision par ordinateur.
MViTv2 : Transformateurs de vision multi-échelle améliorés pour la classification et la détection
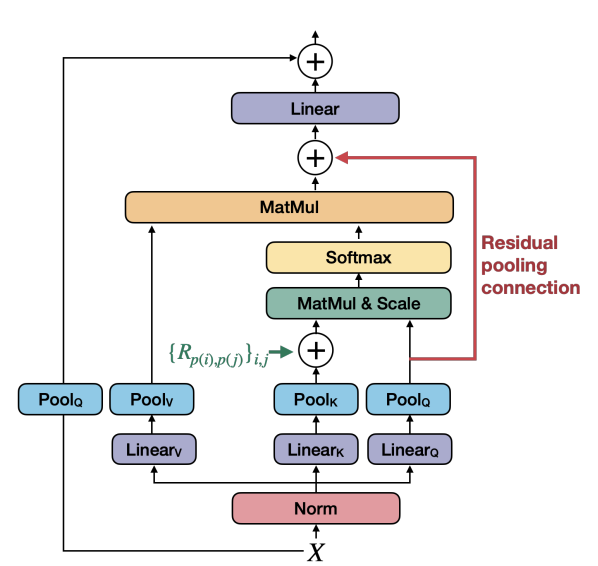
MViTv2 : MViT amélioré (Fan, 2022)
Comme le décrit Haoqi Fan, MViTv2 propose deux principales améliorations techniques par rapport au réseau MViT original.
Tout d'abord, MViTv2 ajoute à l'unité d'attention un encastrement positionnel relatif décomposé invariant par déplacement, comme le montre la flèche verte dans l'image ci-dessus. Dans le modèle MViT, la connexion entre les patchs est déterminée par leur position absolue dans l'image. Ainsi, par exemple, lorsque le transformateur regarde une photo et identifie un arbre, une partie des informations qu'il utilise est l'emplacement exact de l'arbre dans l'image. Cela peut poser un problème de classification de l'arbre dans les images suivantes s'il change de position.
MViTv2 résout ce problème en ajoutant un tenseur d'intégration invariant, qui s'appuie davantage sur les différentes parties de l'image de l'arbre et sur la distance relative qui les sépare. Cela le rend plus robuste lors de l'analyse d'images présentant de légères variations.
Deuxièmement, MViTv2 inclut une connexion de mise en commun résiduelle avec le tenseur de requêtes mises en commun pour compenser la taille plus importante des clés et des valeurs.
Dans mon précédent billet, j'ai mentionné comment les transformateurs de vision multi-échelle utilisent une série de couches d'attention de mise en commun pour construire une compréhension d'une image. Une couche de mise en commun est une technique de sous-échantillonnage de la résolution spatiale de la carte des caractéristiques. Elle simplifie les processus en n'envoyant que les données les plus utiles à l'étape suivante de l'analyse de l'image. Cela permet d'économiser du temps et des ressources et de rendre le modèle moins dépendant des variations des positions des caractéristiques d'une région mise en commun.
MViTv2 conserve certaines de ces données de requête mises en commun, afin de pouvoir les utiliser dans les couches ultérieures du processus. Cela permet aux informations de circuler plus facilement entre les couches. En général, la connexion résiduelle s'est avérée très efficace dans les tâches de vidéo et de vision avec des réseaux neuronaux profonds.
Alors que les transformateurs de vision multi-échelle dont j'ai parlé dans la première partie sont axés sur la vidéo, MViTv2 tente d'aborder d'autres tâches de vision. L'objectif est de créer et de définir une colonne vertébrale unifiée pouvant être utilisée pour les problèmes de classification d'images, de détection d'objets et d'extraction d'informations visuelles de la vidéo.
Malgré les améliorations qu'il apporte, MViTv2 présente certaines limites. Actuellement, de nombreuses recherches sont menées pour rendre les transformateurs de vision moins complexes, afin qu'ils puissent être utilisés sur des appareils mobiles. MViTv2 doit encore être réduit pour pouvoir fonctionner sur des applications mobiles.
De plus, MViTv2 n'a été adapté qu'à des tâches spécifiques de vision limitée. Il serait formidable d'évaluer les performances de MViTv2 sur d'autres bases de données. J'aimerais que sa structure soit optimisée pour être plus générale et facilement ajustable, ce qui permettrait de l'utiliser pour différentes applications sans avoir à procéder à de nombreux ajustements supplémentaires.
MeMViT : Transformateur de vision multi-échelle à mémoire augmentée pour une reconnaissance vidéo efficace à long terme
MeMVIT étend le MViT pour des applications de reconnaissance vidéo à long terme (Wu, 2002). La plupart des modèles actuels d'identification d'actions basés sur la vidéo n'analysent que de courts morceaux de vidéo (entre 2 et 3 secondes). Cependant, MeMVIT peut traiter des vidéos 30 fois plus longues que les modèles de pointe avec une augmentation comparativement faible du coût de calcul. En outre, ce modèle réutilise la mémoire précédemment contenue (comme le montre l'image ci-dessous), ce qui permet de réduire encore le coût de la mémoire. Le fonctionnement du transformateur est ainsi plus léger et moins gourmand en ressources.
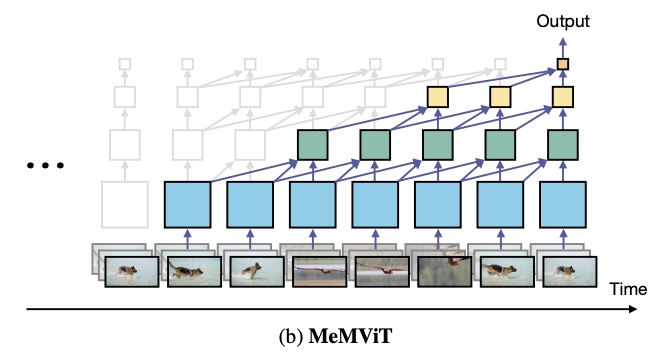
Illustration de la mise à jour de la carte des caractéristiques capturées en fonction des nouvelles images (Wu, 2022)
MeMViT utilise une technique d'apprentissage en ligne qui lui permet de s'adapter aux nouvelles informations sans avoir à s'arrêter et à se réentraîner. Cette approche s'inspire de la façon dont l'œil humain interprète une vidéo en traitant les images une par une, puis en les comparant aux connaissances antérieures. Les paramètres de clé et de valeur du transformateur sont mis à jour en fonction des nouvelles informations.
MViT et ses variantes prennent en compte les propriétés structurelles des réseaux de vision profonde, qui peuvent être précieuses pour les tâches de traitement vidéo et de reconnaissance visuelle. Les variantes présentées à la conférence CVPR 2022 visent à résoudre des problèmes tels que la reconnaissance vidéo à long terme et le traitement de petites différences dans les images. Ces problèmes seront importants lorsque nous essaierons de nous attaquer à des tâches de vision par ordinateur plus complexes, tant dans le domaine de la recherche que dans les applications du monde réel.
Dans la dernière partie de ma série sur la CVPR 2022, je m'éloigne des modèles de transformation de la vision et je jette un coup d'œil à ce que la conférence a offert sur deux techniques qui, selon moi, auront un impact important sur l'avenir de la recherche en vision par ordinateur : l'apprentissage continu et la distillation des connaissances.
L'équipe Advanced Tech d'Amii aide les entreprises à utiliser l'intelligence artificielle pour résoudre certains de leurs défis les plus difficiles. Découvrez comment elle peut vous aider à à exploiter le potentiel des dernières avancées en matière d'apprentissage automatique.
Derniers articles d'actualité

8 avril 2024
Nouvelles
Déchiffrer le code de la conférence
Les boursiers d'Amii partagent des conseils sur la manière de tirer le meilleur parti de votre expérience de la conférence.

26 mars 2024
Nouvelles
Comment le Chat GPT a ruiné le Noël d'Alona | Approximately Correct Podcast
Dans l'épisode de ce mois-ci, Alona explique comment ChatGPT a changé la perception qu'a le public de ce que les modèles de langage d'IA peuvent faire, rendant instantanément obsolètes la plupart des références antérieures, et parle de l'excitation et de l'intensité du travail dans un domaine qui évolue rapidement comme l'IA.

18 mars 2024
Nouvelles
Google Canada annonce de nouvelles subventions de recherche pour renforcer l'écosystème de l'IA au Canada
Google.org annonce de nouvelles subventions de recherche pour soutenir la recherche critique sur l'IA au Canada, axée sur des domaines tels que la durabilité et le développement responsable de l'IA. Les subventions accordées à Amii, à l'Institut canadien de recherches avancées (CIFAR) et au Centre international d'expertise de Montréal sur l'IA (CEIMIA) s'élèvent à un total de 2,7 millions de dollars.
