Nouvelles
Faits saillants de NeurIPS 2023 : Emergence, double descente et apprentissage par renforcement
Revan MacQueen, diplômé d'une maîtrise en sciences, nous fait part de ses trois idées préférées tirées de la conférence.
Neural Information Processing Systems(NeurIPS) est aux conférences sur l'apprentissage automatique ce que Coachella est aux festivals de musique (d'accord, peut-être moins de coups de soleil, mais vous voyez ce que je veux dire). Entre les milliers d'articles, de posters et de participants, l'ampleur de cette conférence est époustouflante.
La conférence est extrêmement interdisciplinaire : des travaux passionnants sont menés dans les domaines de l'apprentissage automatique (ML), des neurosciences, des sciences sociales et de la théorie des jeux, pour n'en citer que quelques-uns. Mais, à la surprise générale, les grands modèles de langage (LLM) ont occupé le devant de la scène cette année.
Un thème que j'ai remarqué au cours de mon exploration était "repenser les récits communs", car de nombreuses études remettaient en question les récits existants en ML en défendant des points de vue alternatifs. Mes trois articles préférés appartiennent tous à cette catégorie et concernent des domaines de recherche différents : LLM, théorie de l'apprentissage statistique et apprentissage par renforcement profond.
L'émergence des LLM en toute clarté
Les capacités émergentes des grands modèles linguistiques sont-elles un mirage ? Schaeffer et al.
Les LLM ont gagné en popularité ces dernières années en raison de l'explosion de leurs performances, mais quelles sont les causes de cette augmentation ? À mesure que la taille des modèles augmente (mesurée en un certain nombre de paramètres), les chercheurs ont remarqué qu'il semble y avoir un point critique où les modèles subissent soudainement des améliorations qualitatives rapides en termes de performance : un effet appelé émergence.
L'émergence dans les LLM est souvent considérée avec un mélange de crainte et d'appréhension. Par exemple, le simple fait de faire passer les FLOP d'entraînement de 10^22 à 10^24 a permis à la précision arithmétique modulaire de GPT-3 de passer de près de 0 % à plus de 30 % ! C'est ce que montre la figure suivante, tirée de l'article, où GPT-3 est représenté par la ligne violette.
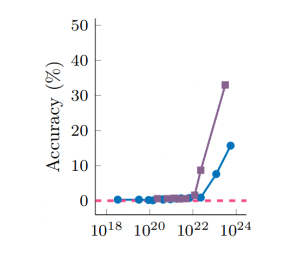
Il est vraiment étonnant de constater que le simple fait d'augmenter la taille des modèles entraîne une augmentation soudaine des capacités. On dirait qu'il se passe quelque chose de vraiment intéressant avec l'émergence, n'est-ce pas ?
Ou peut-être n'est-ce qu'un mirage?
Schaeffer et al. pensent que ce que nous appelons l'émergence dans les LLM est simplement l'effet de l'utilisation d'une métrique non linéaire pour évaluer les modèles. Je m'explique.
La performance des réseaux neuronaux profonds augmente avec la taille de l'ensemble d'apprentissage, la taille du réseau et les ressources de calcul. Schaeffer et al. simplifient cette image en utilisant un modèle mathématique dans lequel la performance (mesurée en perte d'entropie croisée) d'un LLM hypothétique ne dépend que du nombre de paramètres. Les observations empiriques suggèrent que cette relation suit une loi de puissance. Schaeffer et al. utilisent donc cette relation dans leur travail à des fins d'illustration, mais vous pourriez utiliser n'importe quoi.
Supposons que vous utilisiez une perte d'entropie croisée, mais que vous utilisiez une autre mesure pour l'évaluation, par exemple la précision des 5 jetons (1 si les 5 jetons sont sélectionnés correctement par le modèle et 0 sinon). La précision sur 5 jetons est une mesure très non linéaire et, selon Schaeffer et al, cette non-linéarité crée l'illusion de l'émergence.
Supposons que vous commenciez par un modèle minuscule avec une très faible précision sur 5 tokens, et que vous augmentiez progressivement le nombre de paramètres. Au fur et à mesure que vous augmentez le nombre de paramètres, la perte d'entropie croisée diminue de manière assez régulière, mais les performances en matière de précision sur 5 tokens restent médiocres. Cependant, il arrive un moment où, en minimisant la perte d'entropie croisée, le modèle a suffisamment appris pour que la précision sur 5 doigts commence à augmenter. Pour quelqu'un qui ne surveille que la précision sur 5 traits, cela ressemble à une émergence, mais c'est en fait le résultat d'une métrique non linéaire.
Les auteurs démontrent cette hypothèse au moyen de nombreuses expériences. Ils montrent que le fait de modifier la métrique d'évaluation pour qu'elle soit lisse et continue élimine l'effet d'émergence. Ils recréent même artificiellement l'émergence dans des tâches de vision - qui n'ont jamais présenté ces effets auparavant - en concevant une métrique non linéaire appropriée.
Les auteurs précisent qu'ils ne veulent pas impliquer que les LLM ne peuvent pas présenter d'émergence, ils veulent simplement montrer que l'émergence observée précédemment peut être expliquée par une métrique non linéaire. Notre propre observation de l'émergence dans les LLM peut également être expliquée par cette théorie ; nous jugeons la capacité des LLM par des mesures hautement non linéaires, telles que "Peut-il écrire une phrase grammaticalement correcte ?" et "Effectue-t-il les étapes arithmétiques correctes ?".
Repenser la double descente
Un demi-tour sur la double descente : Repenser le comptage des paramètres dans l'apprentissage statistiqueCurth et al. 2023
Dans les cours d'introduction au ML, vous apprenez la relation entre la taille d'un modèle (nombre de paramètres) et sa capacité de généralisation. Avec peu de paramètres, le modèle ne peut pas capturer des modèles complexes. À mesure que le nombre de paramètres augmente, la capacité de représentation s'accroît et la généralisation s'améliore. Cependant, il arrive un moment où des paramètres supplémentaires ne font qu'augmenter la capacité du modèle à s'adapter de manière excessive aux données d'apprentissage, ce qui affaiblit la généralisation. La relation entre le nombre de paramètres (sur l'axe des x) et l'erreur de test présente donc une courbe en forme de "U".
Belkin et al. (2019 ) ont remis en cause cette intuition, en montrant que lorsque le nombre de paramètres dépasse le nombre de points de données dans un ensemble de données, la généralisation recommence à augmenter. Ce phénomène a été surnommé "double descente", car après la courbe en forme de U vient une autre courbe en forme de L. Que se passe-t-il ici ?
Belkin et al. ont suggéré que lorsque le nombre de paramètres dépasse le nombre de points de données, nous entrons dans un nouveau régime dit d'interpolation, où les modèles apprennent des représentations internes efficaces qui interpolent entre les exemples d'apprentissage. Cela expliquerait pourquoi la généralisation s'améliore dans la deuxième descente.
Curth et al. remettent en question cette notion dans leur article intitulé "A U-turn on Double Descent", en proposant qu'il puisse y avoir deux axes différents le long desquels le "nombre de paramètres" peut croître. L'"effet de double descente" est observé lorsque l'on déploie ces deux dimensions en une seule. Cette figure tirée de l'article illustre ce déploiement :
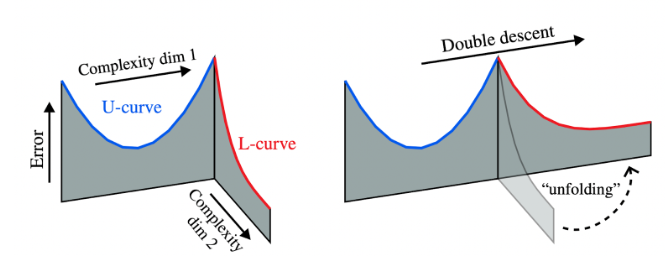
A titre d'exemple, les auteurs démontrent cette hypothèse à l'aide d'arbres de décision. La première dimension est le nombre de feuilles d'un arbre. En augmentant le nombre de feuilles, on obtient une courbe d'erreur-test en forme de U classique. Mais une fois que le nombre de feuilles de l'arbre est égal au nombre de points de données, comment augmenter le nombre de paramètres ? L'une des solutions consiste à augmenter le nombre d'arbres, ce qui donne une forêt aléatoire. Nous entrons ici dans la deuxième descente, où l'augmentation du nombre d'arbres continue à diminuer l'erreur de test. Lorsque nous passons à l'ajout d'arbres, nous ajoutons davantage de paramètres sur une dimension différente de celle où nous n'avons fait qu'augmenter le nombre de feuilles (c'est-à-dire la dimension de complexité 2 dans la figure). Les arbres de décision sont un cas où les deux dimensions sont bien séparables, mais les auteurs montrent quelque chose de similaire pour la régression linéaire (ce qui est un peu trop technique pour un billet de blog, consultez l'article !)
Les auteurs définissent également une mesure généralisée du nombre de paramètres effectifs pour une classe de méthodes appelées lisseurs[Hastie & Tibshirani, 1986], une mesure qui combine différentes dimensions de paramètres d'une manière fondée sur des principes. Les paramètres effectifs redéfinissent l'axe des x des courbes de généralisation et rétablissent les formes classiques en U (ou en L) de ces courbes en comptant plus précisément les paramètres.
Qu'en est-il de l'apprentissage profond ? Ce travail n'aborde pas explicitement l'apprentissage profond, mais il s'agit d'une prochaine étape évidente. L'hypothèse du billet de loterie[Frankle & Carbin, 2018] affirme déjà que les grands réseaux peuvent avoir des "sous-réseaux", auquel cas le réseau plus large peut agréger ces sous-réseaux tout comme les forêts aléatoires agrègent les arbres de décision. À mon avis, une requalification analogue de la double descente pour l'apprentissage profond n'est pas loin.
Quand est-ce que Deep RL en profondeur fonctionner ?
Faire le lien entre la théorie et la pratique de la RL avec l'Horizon EfficaceLaidlaw et al.
Tous ceux qui ont travaillé dans le domaine de la recherche fondamentale savent à quel point il peut être difficile de faire fonctionner ces algorithmes. Le même algorithme donnera d'excellents résultats dans un environnement, mais échouera complètement dans un autre. Il ne semble pas y avoir de caractérisation claire des types d'environnements dans lesquels la NR profonde fonctionnera. Cela s'explique en partie par l'écart important entre la théorie et la pratique : les limites théoriques des performances sont souvent plusieurs ordres de grandeur plus faibles que les performances observées. Pouvons-nous faire mieux ?
Laidlaw et al. cherchent à caractériser les environnements dans lesquels les algorithmes de RL profond seront performants. Cependant, pour déterminer la qualité d'un algorithme, il faut comparer la politique qu'il apprend à la politique optimale, et la politique optimale est inconnue pour de nombreux points de référence standard.
Pour résoudre ce problème, cet article présente BRIDGE, un énorme benchmark de 155 processus de décision de Markov (PDM) déterministes, y compris des jeux Atari et des gridworlds, ainsi que leurs représentations tabulaires. Pour chaque PDM, Laidlaw et al. trouvent la politique optimale à l'aide de sa représentation tabulaire - un énorme effort d'ingénierie puisque certains de ces PDM ont près de 100 millions d'états. Avec ces politiques optimales en main, vous pouvez maintenant déterminer pour quels PDM les algorithmes RL profonds apprendront la politique optimale, et pour quels PDM ils ne l'apprendront pas. Pouvons-nous tirer des conclusions sur ces différents types de PDM ?
Laidlaw et al. remarquent que lorsque le RL profond fonctionne bien dans un environnement, une autre référence naïve (GORP, Greedy Over Random Policy) fonctionne également bien. La méthode GORP consiste à choisir la prochaine action avec avidité en fonction de la fonction Q de la politique aléatoire uniforme. En d'autres termes, GORP choisit la meilleure action à cet état, en supposant qu'il jouera de manière aléatoire par la suite (le GORP réel dans l'article est un peu plus général).
Il s'avère que dans les PDM où GORP trouve la politique optimale, il est probable que l'algorithme RL profond PPO le fasse aussi. Inversement, si GORP ne trouve pas la politique optimale, il est peu probable que PPO le fasse aussi. Ainsi, le RL profond fonctionne dans des environnements qui sont facilement résolus par un algorithme myope, ce qui suggère que ces environnements sont plutôt faciles.
Cette observation a incité Laidlaw et al. à mettre au point une mesure de la complexité de l'environnement appelée horizon effectif. Intuitivement, l'horizon effectif est la distance à laquelle un agent doit se projeter pour déterminer l'action optimale, étant donné que la politique après cet horizon est uniformément aléatoire. L'horizon effectif donne des limites beaucoup plus étroites pour les algorithmes RL profonds et est en corrélation étroite avec les performances du PPO.
La caractérisation des environnements dans lesquels les approches actuelles de RL profond sont performantes est une étape importante vers l'utilisation des algorithmes de RL profond dans le monde réel. Cela nous permet de comprendre quels environnements se prêtent actuellement à de bonnes applications et d'orienter la recherche sur des algorithmes plus performants dans des environnements complexes (avec de vastes horizons effectifs).
Conclusion
Parmi les plus de 3500 articles acceptés à NeurIPS 2023, ces trois travaux se sont distingués pour moi par leurs nouvelles perspectives sur les LLM, la théorie de l'apprentissage statistique et la RL profonde. Ils ont remis en question les récits existants par le biais d'une bonne science - une approche qui, je pense, deviendra de plus en plus courante, car les chercheurs n'ont pas toujours les moyens de calculer pour former des modèles de pointe.
Revan MacQueen est titulaire d'une maîtrise en sciences de l'Université de l'Alberta. Ses recherches portent sur l'apprentissage automatique multi-agents et la théorie des jeux, et sont résumées dans une vidéo d'une minute ici.

