Nouvelles
Instruction Tuning : Améliorer les modèles linguistiques à grande échelle pour de nombreuses tâches
De la rédaction de textes marketing et d'e-mails à la résolution de devoirs 🫣, les grands modèles de langage (LLM) comme ChatGPT semblent capables de tout faire. Il n'est donc pas étonnant qu'ils soient intégrés à des flux de travail dans de multiples contextes.
Au fur et à mesure que ces modèles se généralisent, nous avons constaté que les gens interagissaient avec eux selon un schéma cohérent. Une nouvelle méthode de formation de ces modèles est en train d'émerger, basée sur ce modèle d'utilisation : l'instruction tuning.
Réglez-le comme vous l'utilisez
Lorsque les gens utilisent les MLD, ce qui se passe généralement, c'est que.. :
- Une personne donne des instructions (par exemple : "Écrire un courriel à mon client").
- Ils contiennent des informations supplémentaires (par exemple, nouveau produit disponible, caractéristiques, prix).
- Le mécanisme d'apprentissage tout au long de la vie suit les instructions initiales et tient compte du contexte pour générer sa réponse
Si c'est ainsi que les gens utilisent les LLM, il est logique de les former de la même manière ! L'article Finetuned Language Models are Zero-Shot Learners (Wei et. al.), présente une nouvelle méthode de réglage des instructions qui reflète ce modèle d'utilisation du monde réel, et qui entraîne les LLM à mieux comprendre et suivre les instructions. De manière surprenante, cette méthode améliore également les performances sur de multiples tâches de type "zero-shot" en aval, telles que l'inférence et la traduction, surpassant parfois les modèles spécifiquement entraînés pour la tâche en question.
Qu'est-ce que l'ajustement des instructions ? Avant d'aborder ce sujet, examinons comment la plupart des LLM sont entraînés pour de nouvelles tâches. Normalement, nous commençons par un modèle pré-entraîné et nous l'entraînons avec des données ciblées pour une tâche spécifique. Par exemple, si nous entraînons un modèle pour répondre à des questions de compréhension de lecture, nous commencerons par un modèle pré-entraîné et nous l'entraînerons (finetune) sur un ensemble de données de passages et de questions associées pour qu'il réponde correctement aux questions. Souvent, nous faisons précéder le passage d'une invite du type "Répondez à la question suivante concernant ce passage". Nous testons ensuite ce modèle sur un ensemble de passages et de questions retenus, en indiquant la précision de ces données finales. Le résultat final est un modèle spécifiquement entraîné à répondre à des questions de compréhension de la lecture.
"Nous devrions toujours être critiques lorsque nous considérons la performance des modèles formés d'une nouvelle manière.
Alona Fyshe, boursière Amii et titulaire de la chaire canadienne CIFAR sur l'IA
L'instruction tuning modifie la manière dont nous affinons un modèle. Désormais, au lieu de procéder à un réglage fin sur une tâche spécifique (par exemple, la réponse à une question de compréhension de la lecture), nous nous entraînons sur plusieurs ensembles de données ayant un format similaire mais des tâches différentes. Chaque ensemble de données comporte une invite ou une instruction spécifique (par exemple, répondre à la question suivante, traduire du français à l'anglais) suivie d'un passage, et le modèle doit produire une réponse en tenant compte à la fois de l'instruction et du passage. Le modèle est entraîné sur plusieurs ensembles de données de ce type, mais il est essentiel que les données d'entraînement ne contiennent ni la compétence générale (par exemple, répondre à une question, traduire) ni l'ensemble de données spécifique utilisé pour le test. Ainsi, le test est nul, mais le modèle peut observer le format général des tâches d'instruction (c'est-à-dire, instruction, contexte, génération).
Test du zéro et généralisation dans les modèles adaptés à l'enseignement
Quelle est l'efficacité de l'adaptation des instructions ? Les auteurs constatent que, pour toute une série de tâches, l'adaptation des instructions permet d'améliorer considérablement les performances du modèle "zero-shot". Ils constatent même que leurs performances sont supérieures à celles d'un modèle "few-shot" (formé sur quelques exemples comme ceux de l'ensemble de test) (voir la figure ci-dessous). Il s'agit de résultats impressionnants qui racontent une histoire convaincante.
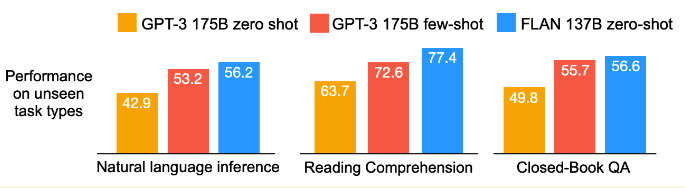
Source : Les modèles linguistiques perfectionnés sont des apprenants de niveau zéro (https://openreview.net/forum?id=gEZrGCozdqR)
Cependant, nous devons toujours faire preuve d'esprit critique lorsque nous examinons les performances des modèles formés d'une nouvelle manière. Quel est exactement le changement qui a conduit à cette amélioration ? FLAN utilise un modèle LaMDA pré-entraîné, qui est différent de GPT-3 tant au niveau de l'architecture que des données d'entraînement. Est-ce la source de l'amélioration ? Les instructions sont-elles vraiment spéciales ? Un autre texte sur le sujet pourrait-il être aussi utile qu'une instruction en langage naturel sur la tâche ?
Pour répondre à la première préoccupation : les auteurs montrent que le modèle LaMDA-PT de base est moins performant que le modèle GPT-3 dans le cadre de l'essai zéro. Par conséquent, le fait de commencer avec le modèle LaMDA pourrait les désavantager légèrement. Il ne semble pas que l'architecture ou les données de pré-entraînement fournissent cet avantage.
Deuxièmement, les instructions sont-elles vraiment si importantes ? Peut-être que le fait que ces modèles soient entraînés sur un ensemble de données supplémentaires est ce qui donne à FLAN son avantage.
Pour tester cette hypothèse, les auteurs expérimentent FLAN sur les données supplémentaires sans instructions et constatent que les performances sont inférieures d'environ 20 points à celles d'un modèle adapté aux instructions (voir la figure ci-dessous). Mais que se passe-t-il si nous utilisons un texte lié à la tâche mais différent de l'instruction ? Pour tester cela, les auteurs ont utilisé le nom de l'ensemble de données au lieu de l'instruction. Cela donne au modèle des informations sur ce qu'il doit faire, mais pas de directives explicites. Là encore, les auteurs constatent que les performances de ce modèle sont inférieures à celles d'un modèle adapté aux instructions. Les instructions semblent donc apporter quelque chose !
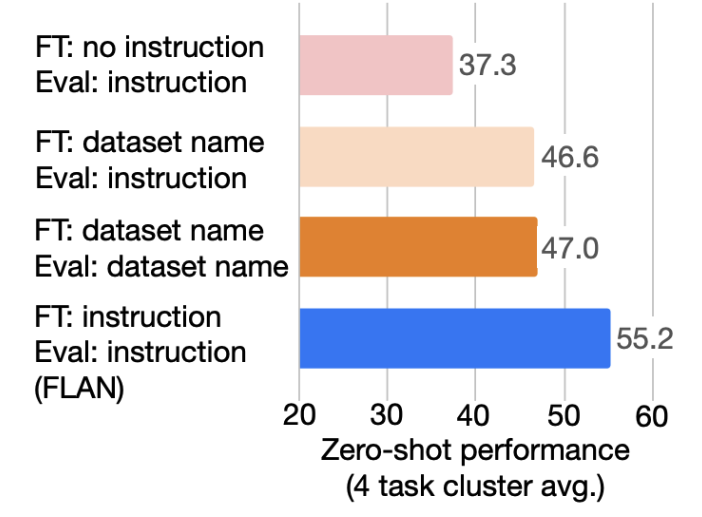
Source : Les modèles linguistiques perfectionnés sont des apprenants de niveau zéro (https://openreview.net/forum?id=gEZrGCozdqR)
Parce que le terme "instruction tuning" ressemble un peu à "prompt tuning". réglage de l'inviteil y a parfois confusion sur ce qui différencie les deux. L'une des grandes différences est que l'accord de l'invite (habituellement) ne met pas à jour les paramètres du LLM, mais accorde plutôt les paramètres d'une invite pour trouver la meilleure façon d'inciter un LLM à effectuer une tâche spécifique. Cela conduit à une autre façon dont les modes accordés à l'invite sont différents : l'accord à l'invite produit des paires modèle-appel qui sont spécifiques à une tâche, alors que les modèles accordés à l'instruction sont prêts à être appliqués à n'importe quelle nouvelle tâche. Par conséquent, si vous voulez un modèle capable de faire beaucoup de choses, il est probable que vous optiez pour un modèle réglé sur les instructions. Si vous souhaitez que votre modèle n'exécute qu'une seule tâche spécifique, vous pouvez envisager l'adaptation des messages-guides.
Conclusion
Voilà en quelques mots ce qu'est l'instruction tuning ! Il s'agit d'une nouvelle façon d'entraîner n'importe quel LLM afin de le rendre plus utile pour une variété d'applications. Pour en savoir plus, consultez l'article : "Finetuned Language Models are Zero-Shot Learners" Wei et al. De plus, quelques modèles adaptés aux instructions sont disponibles au téléchargement ; vous pouvez les trouver sur la page GitHub consacrée à l'adaptation des instructions.
Cet article a été rédigé par la boursière Amii et la chaire CIFAR AI du Canada Alona Fyshe. Alona est également professeur associé à l'Université de l'Alberta, avec une nomination conjointe dans les départements d'informatique et de psychologie. Elle combine ses intérêts en linguistique informatique, en apprentissage automatique et en neurosciences pour étudier la façon dont le cerveau humain traite le langage.
Vous voulez rester au courant des informations sur l'IA ?
Articles connexes

21 mars 2023
Nouvelles
Comment l'IA et le cerveau peuvent apprendre l'un de l'autre : une conférence d'Alona Fyshe
Alona Fyshe présente les similitudes entre le cerveau humain et l'IA et comment tirer parti de cette relation. Découvrez son discours d'ouverture de la Semaine de l'IA 2022.

24 octobre 2023
Nouvelles
Interprétabilité : Le pourquoi de l'IA
Pourquoi l'IA fait-elle les prédictions qu'elle fait ? Alona Fyshe, chercheuse à l'Amii, explore l'interprétabilité de l'IA : son importance, les approches actuelles et les limites connues.
