Nouvelles
Jetez un coup d'œil aux dernières nouveautés en matière de vision par ordinateur lors de la session 2022 de la CVPR : première partie.

Tina Behrouzi, résidente en apprentissage automatique, nous fait part de ses impressions sur ce qu'elle a vu à la conférence CVPR 2022 de cette année.
Tina Behrouzi est résidente en apprentissage automatique au sein de l'équipe Advanced Tech d'Amii. Une grande partie de son travail porte sur la vision par ordinateur, en particulier sur les modèles génératifs profonds pour les tâches de vision. Dans cet article, le premier d'une série de trois, elle partage quelques-unes des avancées qui l'ont le plus enthousiasmée lors de la Conférence sur la vision par ordinateur et la reconnaissance des formes (CVPR) de cette année à la Nouvelle-Orléans.
Cet été, lors de la conférence CVPR 2022, j'ai été surpris par la quantité de nouveaux travaux passionnants présentés, impliquant l'apprentissage continu et les transformateurs de vision.
Dans cette série, je vais examiner certaines de ces avancées. Mais tout d'abord, ce billet vous donnera un aperçu de ce que sont les transformateurs de vision, de l'amélioration rapide de cette technologie et de la façon dont ils pourraient influencer l'avenir de la vision par ordinateur dans les applications d'IA du monde réel.
Une nouvelle façon d'envisager la vision par ordinateur
Cela fait tout juste deux ans que le premier réseau Vision Transformer (ViT) a été présenté par Google Research. Il reprend certaines des leçons tirées des transformateurs dans le traitement du langage naturel et les applique aux images. (Vous pouvez consulter cet article d'AI Summer pour en savoir plus sur le fonctionnement du ViT).
Dès le début, les ViT ont offert des avantages majeurs par rapport aux autres méthodes d'utilisation de l'intelligence artificielle pour analyser et classer les images. Ils peuvent atteindre une précision bien supérieure à celle de méthodes comme les réseaux neuronaux convolutifs. Les modèles ViT sont rapidement devenus très populaires dans presque tous les domaines de la vision, en particulier dans des applications telles que les tâches de vision multimodale (impliquant à la fois du texte et des images) et le traitement vidéo. Les performances impressionnantes de ViT ont été observées dans des modèles tels que DALLE2 et Clip.
Cependant, malgré ses avantages, la ViT souffre toujours de coûts de calcul élevés, en particulier pour les entrées haute résolution et vidéo. Cependant, au cours de ces deux courtes années, nous avons déjà constaté des progrès considérables dans l'amélioration de la ViT, notamment grâce aux transformateurs de vision multi-échelle.
Transformateurs de vision multi-échelle (MViT)
Jitendra Malik est le professeur Arthur J. Chick d'ingénierie électrique et d'informatique à l'université de Californie, à Berkeley. Il est également l'une des figures séminales de la vision par ordinateur. L'affection que Malik a exprimée pour son travail sur les transformateurs de vision multi-échelle lors de la CVPR 2022 m'a immédiatement donné envie de l'approfondir.
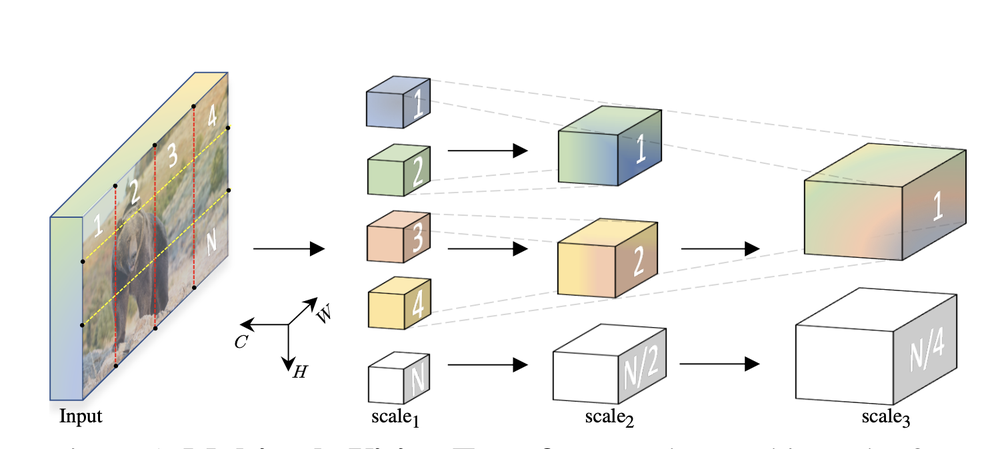
Structure MViT : la taille des canaux augmente et la résolution diminue à chaque étape. (Source : Multiscale Vision Transformers, Facebook AI Research)
La première version de MViT a été publiée lors de la 2021 International Conference on Computer Vision. Les transformateurs et l'auto-attention ont été initialement conçus pour être utilisés dans le traitement du langage naturel (NLP) et ont contribué à un bond en avant massif dans l'amélioration de la façon dont l'intelligence artificielle peut utiliser le langage. Par conséquent, la plupart des travaux sur les ViTs ont porté sur l'amélioration des procédures d'intégration ou d'entraînement des trames et des patchs afin d'obtenir les mêmes succès que ceux observés dans le NLP.
Ce que j'ai vraiment apprécié dans le travail de MViT, c'est la façon dont ils ont utilisé les leçons que nous avons tirées de la prédominance des méthodes de réseaux neuronaux convolutifs profonds pour la vision par ordinateur jusqu'à ce point, et de les utiliser pour informer la façon dont les transformateurs de vision sont structurés. MViT applique les hiérarchies de caractéristiques multi-échelles, qui structurent l'image en un certain nombre de canaux, en commençant par des caractéristiques visuellement denses mais simples, puis en progressant vers l'analyse de caractéristiques plus complexes. Comme le montre l'image ci-dessus, MViT prend les patchs d'entrée avec des caractéristiques visuelles haute résolution de faible dimension et les transfère dans un espace de faible dimension.
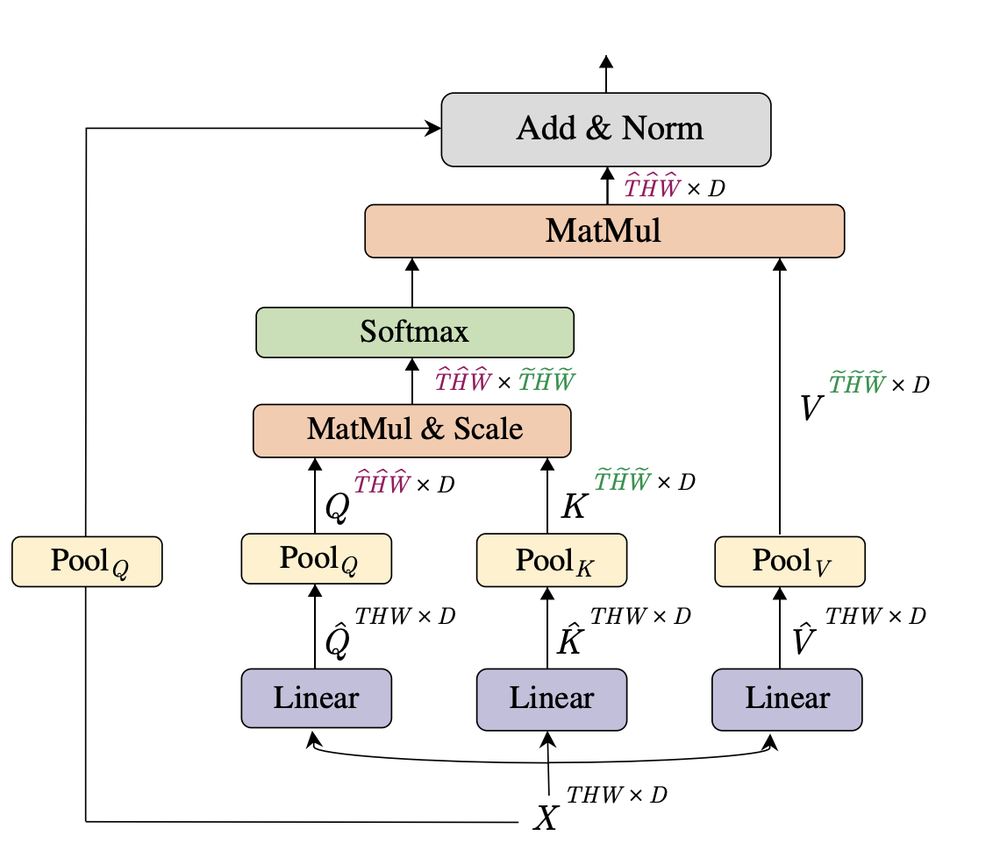
Disposition du transformateur MViT (Source : Multiscale Vision Transformers, Facebook AI Research)
La principale nouveauté de MViT réside dans le mécanisme de mise en commun de l'attention appliqué aux valeurs de clé, de valeur et de requête de chaque couche d'attention. Cette technique de mise en commun réduit considérablement le coût de calcul de l'auto-attention. Par conséquent, MViT nécessite beaucoup moins de mémoire et de ressources de calcul que les autres transformateurs de vision : 60 % d'opérations flottantes en moins par seconde et une précision supérieure de 11 % par rapport à ViT-B.
Ces avancées signifient que les transformateurs de vision multi-échelle pourraient permettre aux machines d'obtenir de meilleurs résultats lorsqu'elles analysent des images et des vidéos dans le monde réel - non seulement avec une plus grande précision, mais aussi plus rapidement et avec moins de formation que les modèles ViT précédents. Cela pourrait contribuer à faire progresser des technologies comme la robotique et les véhicules autonomes pour interagir visuellement avec le monde.
Dans le prochain billet, je me pencherai sur d'autres avancées dans le domaine des MViT, en présentant deux nouveaux modèles développés par le même groupe que celui qui a participé aux travaux ci-dessus.
L'équipe Advanced Tech d'Amii aide les entreprises à utiliser l'intelligence artificielle pour résoudre certains de leurs défis les plus difficiles. Découvrez comment elle peut vous aider à à exploiter le potentiel des dernières avancées en matière d'apprentissage automatique.
Derniers articles d'actualité

24 juillet 2024
Nouvelles
Les humains améliorent l'IA avec Matt Taylor | Approximately Correct Podcast
Comment obtenir les meilleurs résultats lorsque l'IA et les êtres humains travaillent ensemble ? Dans cet épisode d'Approximately Correct, nous nous penchons sur l'IA en boucle avec Matt Taylor, boursier de l'Amii et titulaire de la chaire d'IA du CIFAR au Canada.

22 juillet 2024
Nouvelles
Nouvelles mensuelles d'Amii - Juillet 2024
Lisez notre mise à jour mensuelle sur la croissance de l'écosystème de l'intelligence artificielle en Alberta et sur les possibilités d'y participer.

18 juillet 2024
Nouvelles
Donner du pouvoir aux fondateurs : La collaboration entre Amii et Communitech vise à stimuler l'adoption de l'IA
Amii annonce sa collaboration avec Communitech, un centre d'innovation de la région de Waterloo, afin de fournir aux fondateurs de startups les outils et les ressources d'IA dont ils ont besoin pour intégrer l'IA et développer des capacités internes avec succès. La collaboration s'appuiera sur l'expertise et les ressources d'Amii en matière d'IA et sera centrée sur le programme d'exploration de l'apprentissage automatique (ML Exploration) d'Amii.
