Nouvelles
Le succès de DQN s'explique par l'apprentissage par renforcement "superficiel".
Au moment de la rédaction de cet article, l'auteur invité, Marlos C. Machado, était un étudiant en quatrième année de doctorat au département d'informatique de l'Université de l'Alberta, supervisé par Michael Bowling d'Amii.
Les intérêts de recherche de Marlos se situent largement dans le domaine de l'intelligence artificielle, avec un accent particulier sur l'apprentissage automatique et l'apprentissage par renforcement. Marlos était également membre du groupe de recherche sur l'apprentissage par renforcement et l'intelligence artificielle, dirigé par Richard S. Sutton d'Amii.
En 2013, les chercheurs d'Amii ont proposé l'Arcade Learning Environment (ALE), un cadre qui pose le problème de la compétence générale en IA. L'ALE permet aux chercheurs et aux amateurs d'évaluer des agents d'intelligence artificielle (IA) dans une variété de jeux Atari, en encourageant les agents à réussir sans informations spécifiques au jeu. Bien que cela ne semble pas être un exploit difficile, jusqu'à présent, les agents intelligents ont excellé dans l'exécution d'une seule tâche à la fois, comme les dames, les échecs et le backgammon - toutes des réalisations incroyables !
L'ALE, au contraire, demande à l'IA d'être performante dans de nombreuses tâches différentes : repousser les extraterrestres, attraper des poissons et faire des courses de voitures, entre autres. Vers 2011, Michael Bowling, d'Amii, a commencé à plaider au sein de la communauté des chercheurs en IA en faveur d'un banc d'essai et d'un problème de défi basés sur l'Atari. La communauté a depuis reconnu l'importance des environnements d'arcade, comme en témoigne la sortie d'autres plateformes similaires telles que le GVG-AI, l'OpenAI Gym & Universe, ainsi que le Retro Learning Environment.

1. Jeux Atari 2600 : Space Invaders, Bowling, Fishing Derby et Enduro.
L'ALE doit une partie de son succès à un algorithme de Google DeepMind appelé Deep Q-Networks (DQN), qui a récemment attiré l'attention du monde entier sur l'environnement d'apprentissage et l'apprentissage par renforcement (RL) en général. DQN a été le premier algorithme à permettre un contrôle humain de l'ALE.
Dans ce billet, adapté de notre article intitulé "State of the Art Control of Atari Games Using Shallow Reinforcement Learning", publié en début d'année, nous examinons les principes qui sous-tendent les performances impressionnantes du DQN en introduisant une représentation linéaire fixe qui permet d'atteindre des performances de niveau DQN dans l'ALE.
Les étapes que nous avons suivies pour développer cette représentation mettent en lumière l'importance des biais encodés dans les architectures des réseaux neuronaux, ce qui a permis d'améliorer notre compréhension des méthodes d'apprentissage par renforcement profond. Notre représentation évite également aux agents d'avoir à apprendre des représentations à chaque fois qu'une IA est évaluée dans l'ALE. Les chercheurs peuvent désormais utiliser une bonne représentation fixe tout en explorant d'autres questions, ce qui permet de mieux évaluer l'impact de leurs algorithmes car l'interaction avec les solutions d'apprentissage de représentations peut être mise de côté.
Impact des réseaux Q profonds
Dans l'apprentissage par renforcement, les agents doivent estimer à quel point une situation est "bonne" sur la base des observations actuelles. Traditionnellement, nous, les humains, avons dû définir à l'avance la manière dont un agent traite le flux d'entrée sur la base des caractéristiques que nous jugeons informatives. Ces caractéristiques peuvent aller de la position et de la vitesse d'un véhicule autonome aux valeurs des pixels que l'agent voit dans l'ALE.
Avant le DQN, les valeurs de pixel étaient fréquemment utilisées pour entraîner l'IA dans l'ALE. Les agents apprenaient des éléments de connaissance rudimentaires tels que "lorsqu'un pixel jaune apparaît en bas de l'écran, il est bon d'aller à droite". Bien qu'utiles, les connaissances représentées de cette manière ne peuvent pas coder certains éléments d'information tels que les objets du jeu.
L'objectif de l'ALE étant d'éviter d'extraire des informations propres à un seul jeu, les chercheurs ont dû relever le défi de déterminer comment une IA peut réussir dans plusieurs jeux sans lui fournir d'informations propres à un jeu. Pour relever ce défi, l'agent doit non seulement apprendre comment agir, mais aussi apprendre des représentations utiles du monde.
DQN a été l'un des premiers algorithmes RL capables de le faire avec des réseaux neuronaux profonds.
Pour notre discussion, l'aspect important du DQN est que sa performance est due à l'estimation par le réseau neuronal de la "qualité" de chaque écran, en d'autres termes, de la probabilité qu'un écran particulier donne un résultat favorable.
Il est important de noter que le réseau neuronal comporte plusieurs couches convolutionnelles capables d'apprendre de puissantes représentations internes. Les couches sont construites autour de biais architecturaux simples tels que l'invariance de position/translation et la taille des filtres utilisés. Nous nous sommes demandé quelle part de la performance du DQN résulte des représentations internes apprises et quelle part de l'architecture réseau de l'algorithme. Nous avons implémenté, dans une représentation linéaire fixe, les biais encodés dans l'architecture du DQN et avons analysé l'écart entre notre performance encodée par les biais et la performance du DQN.
À notre grande surprise, notre représentation linéaire fixe a donné des résultats presque aussi bons que le DQN !
Caractéristiques de base et de Blob-Prost
Pour créer notre représentation, nous avons d'abord dû définir ses éléments constitutifs. Nous avons utilisé la méthode mentionnée précédemment consistant à représenter les écrans par "il y a un pixel jaune en bas de l'écran".
Comme l'indique la figure 2 (inspirée de l'article original sur l'ALE), les écrans étaient auparavant définis en fonction de l'existence de couleurs dans des patchs spécifiques de l'image. Les chercheurs divisaient l'image en carrés de 14×16 et, pour chaque carré, codaient les couleurs disponibles dans ce carré.

2. À gauche : capture d'écran du jeu Space Invaders ; au centre : Carrelage utilisé dans tous les jeux ; Droite : Représentation des caractéristiques de base
Dans cet exemple, deux couleurs sont présentes dans la tuile située dans le coin supérieur gauche de l'écran : le noir et le vert. L'agent voit donc la tuile entière comme étant noire et verte, la "quantité" de chaque couleur étant sans importance. Cette représentation, appelée Basic, a été introduite dans l'article original sur l'ALE. Cependant, les caractéristiques Basic ne codent pas la relation entre les tuiles, c'est-à-dire "un pixel vert est au-dessus d'un pixel jaune". Les caractéristiques BASS, qui ne sont pas abordées dans ce billet, peuvent être utilisées comme solution, mais avec des résultats moins que satisfaisants.
Lorsque DQN a été proposé, il a surpassé l'état de l'art dans la grande majorité des jeux. Mais la question restait posée : pourquoi ?
L'une de nos premières constatations a été que les réseaux convolutifs appliquent le même filtre dans tous les différents patchs de l'image, ce qui signifie que les observations ne sont pas nécessairement codées pour un patch spécifique. En d'autres termes, au lieu de savoir "il y a un pixel vert dans la tuile 6 et un pixel orange dans la tuile 8", le réseau sait "qu'il y a un pixel vert à une tuile d'un pixel orange quelque part sur l'écran".
Cette connaissance est utile car nous n'avons plus besoin d'observer les événements à des endroits spécifiques et pouvons les généraliser au moment où ils se produisent. En d'autres termes, l'agent n'a pas besoin d'être touché par un projectile extraterrestre dans chaque espace de pixel possible pour apprendre qu'il est mauvais. L'IA apprend rapidement "un pixel au-dessus du pixel vert (le vaisseau du joueur) est mauvais", quelle que soit la position de l'écran. Nous avons modifié les fonctionnalités de Basic pour qu'elles encodent également de telles informations, en appelant la nouvelle représentation B-PROS.
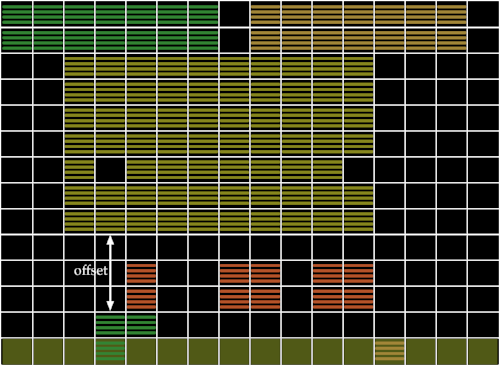
3. Représentation des caractéristiques de B-PROS
B-PROS est limité dans la mesure où il ne code pas le mouvement des objets. S'il y a un projectile à l'écran, se déplace-t-il vers le haut depuis le vaisseau de l'agent ou vers le bas depuis celui d'un extraterrestre ?
Nous pouvons facilement répondre à cette question en utilisant deux écrans consécutifs pour déduire la direction d'un objet, ce que fait le DQN. Au lieu de n'utiliser que les décalages du même écran, nous avons également examiné les décalages entre différents écrans, en codant des choses comme : "Il y avait un pixel jaune deux blocs au-dessus de l'endroit où se trouve maintenant le pixel vert." Nous appelons cette représentation B-PROST.
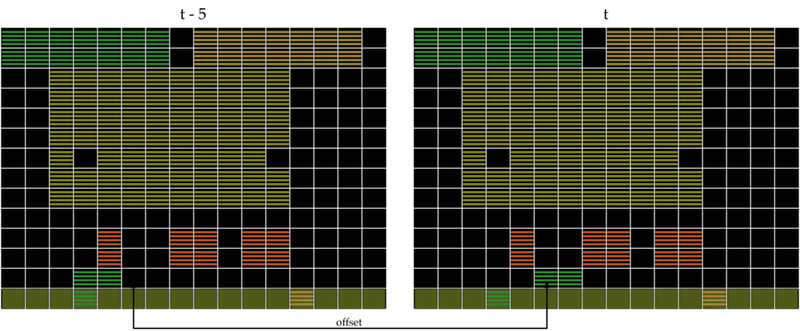
4. Représentation des caractéristiques de B-PROST
Enfin, comme c'est le cas avec le DQN, nous avions besoin d'un moyen d'identifier les objets. La taille des filtres dans le réseau convolutif correspondait à la taille typique des objets dans les jeux Atari. Nous avons donc apporté une modification simple à notre algorithme : au lieu de diviser l'écran en tuiles, nous l'avons divisé en objets pour examiner les décalages entre les objets. Mais comment trouver les objets ?
Nous avons fait la chose la plus simple possible : appeler objet tous les segments dont les pixels sont de la même couleur. Si une couleur en entourait une autre, jusqu'à un certain seuil, nous supposions que l'objet entier avait la couleur environnante et ignorions la couleur à l'intérieur. En prenant les décalages dans l'espace et le temps de ces objets, nous avons obtenu un nouvel ensemble de caractéristiques appelé Blob-PROST. La figure 5 est une simplification de ce que nous avons obtenu.

5. Représentation des objets identifiés pour l'ensemble de caractéristiques Blob-PROST
Alors, quelle est la qualité des caractéristiques de Blob-PROST ? Eh bien, elles obtiennent de meilleurs résultats que DQN dans 21 jeux sur 49 (43 % des jeux), le score de trois des jeux restants ne présentant aucune différence statistiquement significative avec celui de DQN. Même lorsqu'un algorithme est comparé à lui-même, nous nous attendons à ce qu'il gagne dans 50 % des cas, ce qui fait de nos 43 % un résultat comparable.
Conclusion
Nous avons commencé par nous demander quelle part de la performance originale du DQN résultait des représentations qu'il apprend par rapport aux biais déjà encodés dans le réseau neuronal : invariance de position/translation, informations sur les mouvements et détection d'objets. À notre grande surprise, les biais expliquent une grande partie de la performance du DQN. En codant simplement les biais sans apprendre aucune représentation, nous avons pu obtenir des performances similaires à celles du DQN.
La capacité d'apprendre des représentations est essentielle pour les agents intelligents : les représentations fixes, bien qu'utiles, constituent une étape intermédiaire sur la voie de l'intelligence générale artificielle. Bien que les performances de DQN puissent s'expliquer par les biais du réseau convolutif, l'algorithme constitue une étape majeure, et les travaux ultérieurs ont montré l'importance des principes introduits par l'équipe de recherche. L'état de l'art est maintenant dérivé de DQN, atteignant des scores encore plus élevés dans les jeux Atari et suggérant que de meilleures représentations sont maintenant apprises.
Pour une discussion plus détaillée de chacun des biais évalués, ainsi que des performances de DQN par rapport à Blob-PROST, lisez notre article : "State of the Art Control of Atari Games Using Shallow Reinforcement Learning".
Derniers articles d'actualité

7 novembre 2024
Nouvelles
AI for Good : exploiter l'IA pour sécuriser les espaces en ligne des communautés autochtones
Amii s'associe à pipikwan pêhtâkwan et à sa jeune entreprise wâsikan kisewâtisiwin pour exploiter l'IA afin de lutter contre la désinformation au sujet des peuples autochtones et d'inclure ces derniers dans le développement de l'IA. Le projet est soutenu par l'engagement de PrairiesCan à accélérer l'adoption de l'IA par les PME de la région des Prairies.

7 novembre 2024
Nouvelles
Russ Greiner est nommé lauréat du Prix Brockhouse du Canada 2024
Russ Greiner, boursier Amii et titulaire de la chaire CIFAR AI du Canada, et David Wishart, chercheur et collaborateur de l'Université de l'Alberta, ont reçu le prix Brockhouse Canada pour la recherche interdisciplinaire en sciences et en ingénierie, décerné par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG).

6 novembre 2024
Nouvelles
Jonathan Schaeffer, membre fondateur d'Amii, prend sa retraite de l'université après 40 ans de travail dans le domaine de l'IA.
Jonathan Schaeffer, membre fondateur d'Amii, a passé 40 ans à avoir un impact considérable sur la théorie des jeux et l'IA. Aujourd'hui, il se retire du monde universitaire et partage certaines des connaissances qu'il a acquises au cours de son impressionnante carrière.
