Nouvelles
Lecture recommandée : Pourquoi l'IA qui s'auto-apprend à atteindre un objectif est la prochaine grande nouveauté ?
Matthew E. Taylor (professeur agrégé, Université de l'Alberta), boursier Amii et titulaire de la chaire d'IA de l'ICAR au Canada, a coécrit un article pour la Harvard Business Review sur les raisons pour lesquelles l'IA qui s'apprend à atteindre un objectif est la prochaine grande chose. L'article est coécrit avec Kathryn Hume, chef intérimaire de Borealis AI, le laboratoire de recherche en apprentissage automatique de la Banque Royale du Canada.
Les chercheurs d'Amii sont des pionniers et des leaders dans le domaine de l'apprentissage par renforcement (RL), une branche de l'apprentissage automatique qui permet aux systèmes d'IA d'apprendre par l'expérience. Les systèmes d'apprentissage par renforcement interagissent avec leur environnement, souvent par essais et erreurs, et obtiennent des récompenses positives ou négatives en fonction de leurs actions. Les humains définissent la tâche globale et les récompenses pertinentes que le système utilise pour découvrir la meilleure action à entreprendre dans une situation donnée.
Au lieu de recevoir des instructions sur les actions à entreprendre pour atteindre un objectif, le système doit apprendre quelles actions sont les plus gratifiantes en les essayant. Au fil du temps, le système développe une politique (ou une façon d'agir) qui lui permet de sélectionner l'action qui permettra le mieux d'atteindre l'objectif, ce qui peut nous aider à découvrir les actions optimales à entreprendre dans un scénario donné.
L'apprentissage par renforcement peut être utilisé pour l'optimisation et l'amélioration des processus, dans le cadre d'un système de recommandation ou de tutorat intelligent, ainsi que pour le contrôle adaptatif et la prise de décision dans les systèmes autonomes.
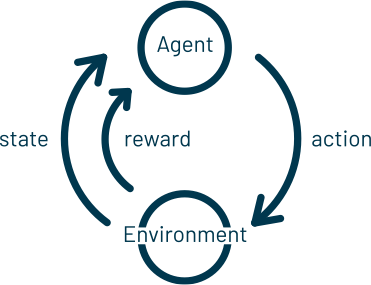
En mettant l'accent sur l'apprentissage fondé sur l'expérience pour la prise de décision, l'apprentissage par renforcement diffère des autres types d'apprentissage automatique comme l'apprentissage supervisé, qui nécessite des données étiquetées en entrée, ou l'apprentissage non supervisé, qui se concentre sur la recherche de similitudes et de différences entre les points de données.
Sur l'apprentissage par renforcement, les auteurs de l'article expliquent : "Des entreprises comme Netflix, Spotify et Google ont commencé à l'utiliser, mais la plupart des entreprises sont à la traîne. Pourtant, les opportunités sont partout. En fait, chaque fois que vous devez prendre des décisions en séquence - ce que les praticiens de l'IA appellent des tâches de décision séquentielle - il y a une chance de déployer l'apprentissage par renforcement."
Nous nous sommes entretenus avec M. Taylor, qui dirige le laboratoire d'apprentissage des robots intelligents à l'université de l'Alberta, où ses recherches actuelles portent sur les améliorations fondamentales de l'apprentissage par renforcement, l'application de l'apprentissage par renforcement à des problèmes du monde réel et l'interaction homme-IA.
"La plupart des gens reconnaissent que l'IA et l'apprentissage automatique changent le monde à bien des égards, et il y a cette technique sous-utilisée de l'apprentissage par renforcement qui devrait être utilisée de toutes les manières différentes", explique Taylor. "Lorsque plus de gens comprennent l'apprentissage par renforcement, ils accueillent plus d'opportunités d'utiliser cette technologie pour faire quelque chose de nouveau et d'utile dans leurs entreprises."
L'article poursuit : "Bien que l'apprentissage par renforcement soit une technologie mature, elle commence seulement à être appliquée dans les entreprises. La technologie brille lorsqu'elle est utilisée pour automatiser ou optimiser des processus d'entreprise qui génèrent des données denses, et où il pourrait y avoir des changements imprévus que vous ne pourriez pas saisir avec des formules ou des règles. Si vous êtes en mesure de repérer une opportunité et de vous appuyer sur une équipe technique interne ou de vous associer à des experts dans ce domaine, vous avez la possibilité d'appliquer cette technologie pour devancer vos concurrents."
L'article fournit une vue d'ensemble digeste de l'apprentissage par renforcement, ainsi que des exemples de la manière dont les entreprises utilisent actuellement cette technique. L'article apprend également aux hommes d'affaires comment repérer une opportunité d'apprentissage par renforcement en cinq étapes :
- Faites une liste d'inventaire de ce que vous essayez d'atteindre.
- Envisager d'autres options et d'autres techniques, le cas échéant
- Faites attention à ce que vous souhaitez et réfléchissez bien aux résultats que vous souhaitez obtenir.
- Déterminer si l'utilisation de RL en vaut la peine
- Préparez-vous à être patient
"Nous sensibilisons des personnes qui n'auraient peut-être jamais entendu parler de cette technologie pour qu'elles en apprennent davantage et constatent qu'elle peut changer la donne pour elles lorsqu'il s'agit de résoudre un large éventail de problèmes", explique M. Taylor.
Lisez l'article complet de la Harvard Business Review ici.
Apprenez-en plus sur l'apprentissage par renforcement dans la spécialisation en apprentissage par renforcement offerte par l'Université de l'Alberta et Amii sur CourseraCe cours a été élaboré et dispensé par Martha White et Adam White, boursiers et titulaires de la chaire d'IA de l'ICAR Canada avec Amii.
Derniers articles d'actualité

8 avril 2024
Nouvelles
Déchiffrer le code de la conférence
Les boursiers d'Amii partagent des conseils sur la manière de tirer le meilleur parti de votre expérience de la conférence.

26 mars 2024
Nouvelles
Comment le Chat GPT a ruiné le Noël d'Alona | Approximately Correct Podcast
Dans l'épisode de ce mois-ci, Alona explique comment ChatGPT a changé la perception qu'a le public de ce que les modèles de langage d'IA peuvent faire, rendant instantanément obsolètes la plupart des références antérieures, et parle de l'excitation et de l'intensité du travail dans un domaine qui évolue rapidement comme l'IA.

18 mars 2024
Nouvelles
Google Canada annonce de nouvelles subventions de recherche pour renforcer l'écosystème de l'IA au Canada
Google.org annonce de nouvelles subventions de recherche pour soutenir la recherche critique sur l'IA au Canada, axée sur des domaines tels que la durabilité et le développement responsable de l'IA. Les subventions accordées à Amii, à l'Institut canadien de recherches avancées (CIFAR) et au Centre international d'expertise de Montréal sur l'IA (CEIMIA) s'élèvent à un total de 2,7 millions de dollars.
