Au cours des dernières décennies, le secteur canadien de l'énergie a connu une augmentation annuelle substantielle de 40 000 barils par jour de la production de pétrole de schiste, selon le régulateur canadien de l'énergie. Les ressources de schiste englobent les réserves non conventionnelles de pétrole et de gaz qui se trouvent dans les profondeurs des formations rocheuses. Malheureusement, les processus d'extraction associés aux ressources de schiste sont souvent inefficaces, ce qui entraîne des déchets matériels importants qui ont un impact direct sur l'environnement. Pour résoudre les problèmes environnementaux, le gouvernement a mis l'accent sur la réduction des émissions et l'amélioration de l'efficacité de l'industrie pétrolière et gazière, dans le but d'atténuer son impact sur le changement climatique.
Une nouvelle technologie de complétion de plus en plus populaire, appelée CTFSS (coiled tubing-enabled fracturing sliding sleeve), a montré qu'elle pouvait améliorer l'efficacité de l'extraction des ressources de schiste. Cette approche utilise un tube enroulé pour transporter un outil de commutation qui ouvre ou ferme le manchon coulissant, ce qui améliore l'efficacité du travail.
Cependant, le processus d'ouverture ou de fermeture des manchons coulissants est compliqué, et les erreurs peuvent entraîner des opérations incomplètes et une augmentation des coûts. Par exemple, l'ouverture des manchons nécessite parfois plusieurs tentatives ou induit les opérateurs en erreur en les faisant passer à l'étape suivante, comme le démarrage prématuré de la fracturation. Il en résulte un processus moins efficace et un gaspillage important de matériel, qui peut coûter entre 10 000 et 100 000 USD par manchon.
Lorsque cette incertitude survient au cours de la phase d'achèvement, le recyclage de l'outil peut nécessiter environ deux fois le temps de traitement pour chaque étape, en raison des tentatives répétées. Actuellement, la seule option pour capturer les événements en fond de puits pendant les opérations de fracturation consiste à déployer une caméra à l'intérieur du puits, ce qui est une solution coûteuse.
Amii et Kobold Completions Inc. se sont associés pour développer une nouvelle méthode d'identification des incidents liés aux manchons en utilisant l'apprentissage automatique et la technologie propriétaire de Kobold. L'approche innovante est détaillée dans un récent article publié par l'équipe. Il s'agit d'une alternative pionnière, qui utilise les données de fond de puits (GuideHawk©) et la capture des signaux de vibration de surface grâce au système Echo©. Cette approche s'appuie sur des techniques d'apprentissage automatique pour identifier efficacement les incidents liés aux manchons. L'installation et l'intégration des dispositifs Echo et Guidehawk sont simples, ce qui permet de les adapter à différents contextes de travail. Les deux outils utilisent des capteurs familiers utilisés par d'autres dispositifs analogues dans les champs pétrolifères. Cette approche constitue une solution rentable et in situ par rapport aux méthodes existantes.
Cadre XGSleeve
Dans ce projet, nous proposons deux cadres : l'un pour les données Guidehawk© (séries temporelles multivariées) et l'autre pour les données Echo© (séries temporelles univariées). L'utilisation d'un modèle de Markov caché (HMM) pour les données Echo© afin d'extraire les caractéristiques liées aux étapes des opérations de fracturation peut améliorer l'apprentissage du modèle, car il capture la relation entre les étapes des événements, d'autant plus que les données brutes d'Echo ne consistent qu'en une seule mesure de la valeur de choc.
Modèle Guidehawk
Le cadre proposé pour l'analyse des données Guidehawk© vise à former un modèle XGBoost pour l'identification des incidents d'ouverture de manche. Le processus commence par la collecte de données provenant des sources GuideHawk et Echo après l'achèvement des opérations de fracturation.
Les données GuideHawk© - qui englobent la pression de la bobine et de l'anneau, la déformation, les chocs, la température et le couple, ainsi que les données de vibration de surface (chocs) d'Echo - sont recueillies et transférées à un dispositif périphérique. Ce dernier compile les données collectées dans un fichier JSON structuré, en les classant par ordre chronologique sur la base des horodatages. Ce fichier JSON est ensuite téléchargé dans Cosmos DB, qui sert de référentiel pour les données provenant de divers travaux de fracturation menés au Canada.
Dans l'environnement en nuage, les données GuideHawk© sont soumises à des procédures d'extraction et d'ingénierie des caractéristiques. Les caractéristiques temporelles et statistiques sont extraites pour créer un ensemble de données enrichi. Le modèle XGBoost, initialement formé à l'aide des données GuideHawk©, se charge ensuite de générer des étiquettes pour les nouveaux travaux de fracturation. Ces étiquettes générées sont intégrées avec leurs horodatages respectifs. L'ensemble de données final comprend à la fois ces étiquettes ajoutées et les données Echo© correspondantes.
À la fin de ce processus, le modèle XGSleeve est entraîné à l'aide de cet ensemble de données amélioré. L'objectif est d'augmenter les capacités prédictives pour les travaux de fracturation à venir, en améliorant encore la compréhension et la prévision des incidents liés à l'ouverture des manchons.
Modèle XGSleeve pour les données Echo©.
Une fois la formation au modèle XGSleeve terminée, son déploiement sur le terrain permet aux opérateurs de prendre des décisions éclairées en temps réel. Le processus commence par l'enregistrement continu des valeurs de choc sur la tête de puits par les données Echo©, qui sont ensuite sous-échantillonnées à un échantillon par seconde. Ces données sont ensuite transmises à un dispositif périphérique pour la prédiction du modèle ML.
Le modèle XGSleeve fonctionne sur l'appareil périphérique, en commençant par l'utilisation du HMM pré-entraîné pour dériver les probabilités de grappes pour chaque horodatage. Ces probabilités servent ensuite d'entrées pour le modèle XGBoost suivant. Les caractéristiques temporelles et statistiques sont ensuite extraites. Dans la phase suivante d'ingénierie des caractéristiques, le modèle XGBoost évalue l'horodatage actuel à l'aide des caractéristiques extraites, produisant ainsi des probabilités liées à chaque occurrence d'incidents d'ouverture et de fermeture.
Ces probabilités sont ensuite transmises au dispositif de surveillance de l'opérateur, ce qui facilite la visualisation en temps réel de la situation en cours. Fort de ces informations, l'opérateur est en mesure de prendre des décisions en toute connaissance de cause, qu'il s'agisse de retenter la procédure d'ouverture ou de passer aux étapes suivantes de l'opération. L'intégration du modèle XGSleeve dans les opérations sur le terrain renforce considérablement l'efficacité et la sécurité, en offrant une aide cruciale pour une prise de décision rapide et précise pendant les procédures de fracturation critiques.
 Exploiter la puissance du modèle de Markov caché
Exploiter la puissance du modèle de Markov caché
Dans ce projet, les opérations de fracturation se déroulent en différentes étapes, comme la libération d'un outil de fond de trou, le passage à la manche suivante, l'ouverture de la manche et la fracturation proprement dite. L'utilisation du regroupement HMM permet d'extraire des informations plus complètes que la méthode de roulement de fenêtre ou les valeurs de décalage. Une chose utile que nous pouvons trouver est la probabilité que chaque période de temps soit dans chaque groupe. Cela nous permet de savoir quelle étape de fracturation se produit dans un certain point de données. Ces informations supplémentaires peuvent nous aider à comprendre comment les étapes de fracturation se succèdent.
Tout d'abord, nous formons le HMM dans le groupe d'entraînement à l'aide d'une bibliothèque appelée hmmlearn. Nous avons choisi un modèle de Markov caché avec une distribution gaussienne parce que nos données ressemblent à une distribution normale, en particulier les données Echo. Nous utilisons la méthode de maximisation des attentes (EM) pour l'algorithme d'apprentissage. Nous commençons par deviner les paramètres du modèle (comme la probabilité de chaque étape, leur évolution, la moyenne et l'écart) de manière aléatoire, avec quelques exemples réels. Pendant l'apprentissage, le modèle modifie ces paramètres pour les adapter aux exemples réels. Nous entraînons ce modèle de Markov caché pendant 100 essais.
Pour trouver le meilleur nombre de groupes, nous utilisons la méthode du coude. Sur la base de la méthode du coude, nous avons sélectionné le nombre raisonnable de 5 comme nombre de groupes. Nous avons ensuite formé un modèle HMM avec 5 grappes et utilisé les probabilités résultantes pour chaque grappe comme un ensemble de caractéristiques supplémentaires en combinaison avec les caractéristiques temporelles et statistiques. L'incorporation d'informations de regroupement en tant qu'entrée supplémentaire dans le modèle XGBoost a entraîné une amélioration notable du score F1.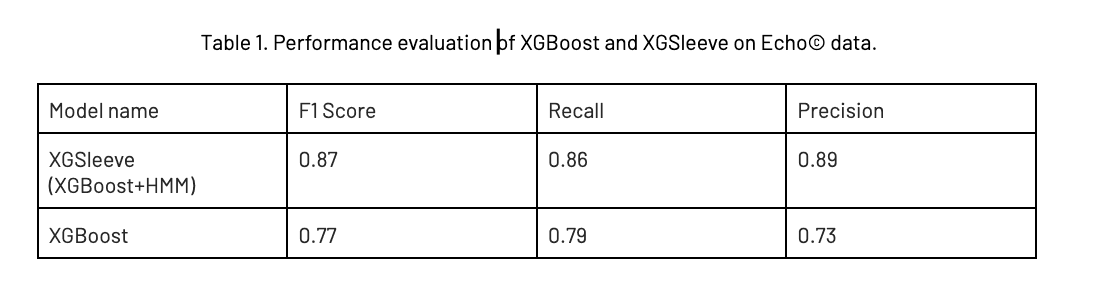 La couleur verte met en évidence les pas de temps qui appartiennent à chaque groupe, tandis que la couleur violette met en évidence les étiquettes. Les grappes 3 et 4 peuvent sembler identiques en raison de la faible résolution, mais elles représentent indifféremment des pics de signal à long terme. Le groupe 5 représente les temps d'arrêt et les changements d'étape d'un puits à l'autre. Les groupes 2 et 1 représentent les cas où l'outil relâche la pression pour passer au puits suivant. Nous pouvons observer que les groupes 3 et 4 représentent étroitement les étiquettes, qui sont surlignées en violet.
La couleur verte met en évidence les pas de temps qui appartiennent à chaque groupe, tandis que la couleur violette met en évidence les étiquettes. Les grappes 3 et 4 peuvent sembler identiques en raison de la faible résolution, mais elles représentent indifféremment des pics de signal à long terme. Le groupe 5 représente les temps d'arrêt et les changements d'étape d'un puits à l'autre. Les groupes 2 et 1 représentent les cas où l'outil relâche la pression pour passer au puits suivant. Nous pouvons observer que les groupes 3 et 4 représentent étroitement les étiquettes, qui sont surlignées en violet. Nouveaux horizons
Nouveaux horizons
La capacité de XGSleeve à exploiter la puissance des modèles de Markov cachés (HMM) pour comprendre les séquences d'étapes et utiliser ces informations pour détecter efficacement les incidents de manchon marque une avancée notable dans le domaine des processus de complétion de puits. Les concepts sous-jacents qui sous-tendent les algorithmes de regroupement robustes de XGSleeve pourraient ouvrir la voie à de nouveaux défis en matière de classification des séries temporelles et de traitement de données de capteurs complexes dans le monde réel, en particulier dans les scénarios où les processus se déroulent de manière séquentielle.
Auteurs
Sahand Somi
Jubair Sheikh